Mapping Indian soils at scale
In India, a wealth of soil analytical data are generated by soil sampling programs such as the All India Soil Sampling Program and the Soil Health Card scheme. These rich data assets allow scientists to use state-of-the-art technologies and methods to produce digital maps of key soil fertility parameters that can support bringing soil fertility recommendations to scale.
Digital soil mapping (DSM), defined as the ‘computer-assisted production of digital maps of soil types and soil properties,’ makes use of (geo)statistical models that predict the soil type or property from a limited number of soil observations from a sample data set for locations where no samples have been taken. These ‘unsampled locations’ are typically arranged on a regular grid, i.e. DSM produces gridded (raster) soil maps at a specific spatial resolution (grid cell or pixel size) with a spatial prediction made for each individual grid cell.
Adopting DSM methods, combined with intelligent sampling design, could reduce the strain on the soil testing system in terms of logistics, quality control and costs. Improving digital soil mapping practices can also help create the infrastructure for a soil intelligence system that can drive decision-making at scale.
In November 2017, the Cereal Systems Initiative for South Asia (CSISA) engaged Dr. Bas Kempen of ISRIC – World Soil Information to provide a 5-day, hands-on training on digital soil mapping to 17 participants from Bihar, Andhra Pradesh and Odisha. Held at the Andhra Pradesh Space Applications Centre in Vijayawada, the training focused on capacity development and the generation of fine-scale digital soil maps at state and district levels using local data.
The training started by covering the essentials of ‘R,’ which is a useful, free statistical software. The group then learned about quantifying and modeling spatial variation with a variogram, followed by discussions about geostatistics and a machine learning algorithm called ‘random forest’, a powerful algorithm to model the predictive relationship between the soil property of interest and a (large) set of environmental covariates. Next, the participants focused on data preparation, which included organizing soil sample and covariate data, creation of a prediction mask, creation of a covariate stack and the regression matrix (soil sample data set with covariate data associated to each sampling site). The participants worked on a hands-on data preparation exercise using a soil sample data set from Bihar.
The latter part of the training was dedicated to validation and a hands-on DSM exercise using local data. On the last day of the training, the participants finalized and presented their maps, energized that they had produced digital soil maps using local data. The workshop concluded with the identification of follow-up actions that can lead towards the better use of spatial data analytics and DSM methods for bringing improved soil fertility management to scale.
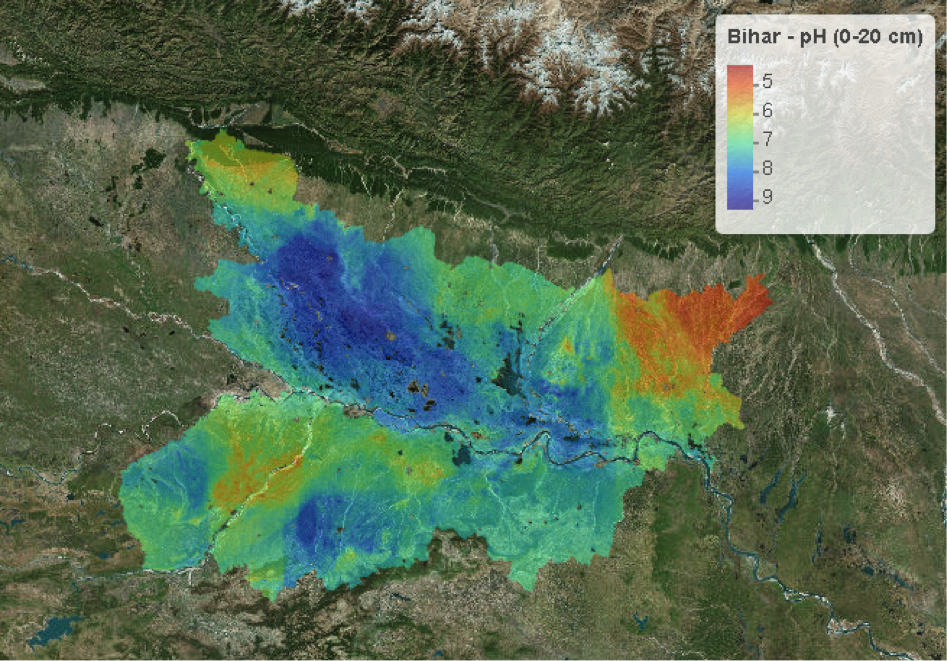
In January 2018, to reinforce the skills taught by Dr. Kempen, CSISA engaged Dr. David G. Rossiter, Adjunct Associate Professor at Cornell University and Guest Researcher at ISRIC, to provide follow-up training on advanced spatial data quality assessments, cleaning and curation, as well as to provide direct mentorship to DSM trainees on the improvement of their ‘first generation’ digital soil maps. First generation maps for soil properties such as critical micronutrients like Zinc and soil pH have been produced and are being validated against field data. Implications for insights into efficient soil sampling at scale are being derived from the maps while critical use cases such as the deployment of predictive maps for precision nutrients management at scale are being evaluated.
In partnership with state government agencies and the Bill & Melinda Gates Foundation, CSISA will continue to provide training and support to these initial participants as well as others, working to expand DSM capacity in India for the efficient and rapid scaling of soil fertility recommendations for farmers.